Abstract¶
The Rubin Science Platform provides an IVOA TAP service that returns structured information about Rubin Observatory data products. To allow easy user exploration of that data, particularly via the Portal Aspect, we’ve identified at least three types of information that we may want to associate with the returned records: how to download the image associated with an observation, how to retrieve a cutout of that image, and additional related TAP queries that the user may wish to explore. We expect to have additional similar use cases in the future. This tech note describes how we meet those requirements using the IVOA DataLink protocol and the datalinker web service.
DataLink introduction¶
The goal of the IVOA DataLink standard is to provide a mechanism to link from metadata about datasets to the data itself, related data products, and web services that can operate on the data. Most directly relevant for the purposes of this tech note, it defines two standards: a web service that provides links for a given identifier, and a general way of extending a VOTable with links to associated services. We use the first standard to provide access to the image associated with a record and a pointer to the image cutout service, and the second to provide pointers to related TAP queries.
The links service is a DALI web service that takes as input one or more identifiers and returns a VOTable of links and services associated with that identifier. Here is an example from the Science Platform links service:
<?xml version="1.0" encoding="utf-8"?>
<VOTABLE version="1.4" xmlns="http://www.ivoa.net/xml/VOTable/v1.3"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.ivoa.net/xml/VOTable/v1.3 http://www.ivoa.net/xml/VOTable/VOTable-1.4.xsd">
<RESOURCE type="results">
<TABLE>
<DESCRIPTION>Links table for observation dataset butler://dp02/f103ce60-9445-4029-9feb-d244c1a1932a</DESCRIPTION>
<FIELD ID="ID" arraysize="*" datatype="char"
name="ID" ucd="meta.id;meta.main"/>
<FIELD ID="access_url" arraysize="*" datatype="char"
name="access_url" ucd="meta.ref.url"/>
<FIELD ID="service_def" arraysize="*" datatype="char"
name="service_def" ucd="meta.ref"/>
<FIELD ID="error_message" arraysize="*" datatype="char"
name="error_message" ucd="meta.code.error"/>
<FIELD ID="description" arraysize="*" datatype="char"
name="description" ucd="meta.note"/>
<FIELD ID="semantics" arraysize="*" datatype="char"
name="semantics" ucd="meta.code"/>
<FIELD ID="content_type" arraysize="*" datatype="char"
name="content_type" ucd="meta.code.mime"/>
<FIELD ID="content_length" datatype="long"
name="content_length" ucd="phys.size;meta.file" unit="byte"/>
<DATA>
<TABLEDATA>
<TR>
<TD>butler://dp02/f103ce60-9445-4029-9feb-d244c1a1932a</TD>
<TD><![CDATA[URL]]></TD>
<TD/>
<TD/>
<TD>Primary image or observation data file</TD>
<TD>#this</TD>
<TD>application/fits</TD>
<TD>108478080</TD>
</TR>
<TR>
<TD>butler://dp02/f103ce60-9445-4029-9feb-d244c1a1932a</TD>
<TD/>
<TD>cutout-sync</TD>
<TD/>
<TD>Cutout service (SODA sync)</TD>
<TD>#cutout</TD>
<TD>application/fits</TD>
<TD/>
</TR>
</TABLEDATA>
</DATA>
</TABLE>
</RESOURCE>
<RESOURCE ID="cutout-sync" type="meta" utype="adhoc:service">
<GROUP name="inputParams">
<PARAM arraysize="*" datatype="char" name="ID" ucd="meta.id;meta.dataset"
value="butler://dp02/f103ce60-9445-4029-9feb-d244c1a1932a">
<DESCRIPTION>Publisher DID of the dataset of interest</DESCRIPTION>
</PARAM>
<PARAM arraysize="*" datatype="double" name="POLYGON"
ucd="pos.outline;obs" unit="deg" value="" xtype="polygon">
<DESCRIPTION>A polygon (as a flattened array of ra, dec pairs) that
should be covered by the cutout.</DESCRIPTION>
</PARAM>
<PARAM arraysize="3" datatype="double" name="CIRCLE"
ucd="pos.outline;obs" unit="deg" value="" xtype="circle">
<DESCRIPTION>A circle (as a flattened array of ra, dec, radius)
that should be covered by the cutout.</DESCRIPTION>
</PARAM>
</GROUP>
<PARAM arraysize="*" datatype="char" name="accessURL" ucd="meta.ref.url"
value="https://data.lsst.cloud/api/cutout/sync"/>
<PARAM arraysize="*" datatype="char" name="standardID"
value="ivo://ivoa.net/std/SODA#sync-1.0"/>
</RESOURCE>
</VOTABLE>
The full URL to the image (a signed GCS or S3 URL, see Links service) has been replaced for URL for brevity.
The cutout-sync resource above is an example of adding service descriptors to a VOTable.
This can be done to any VOTable, not just the links table returned by the links service.
For example, here is a service descriptor that we attach to a TAP result on the Object table that allows the user to retrieve a light curve for the object.
<RESOURCE type="meta" utype="adhoc:service">
<DESCRIPTION>Retrieve ForcedSource time series</DESCRIPTION>
<PARAM name="accessURL" datatype="char" arraysize="*" value="https://data.lsst.cloud/api/datalink/timeseries" />
<PARAM name="standardID" datatype="char" arraysize="*" value="lsst://api.data.lsst.cloud/datalink/timeseries#v0.1" />
<GROUP name="inputParams">
<PARAM name="id" datatype="long" ucd="meta.id" ref="col_333" value="">
<DESCRIPTION>Object ID for time series</DESCRIPTION>
</PARAM>
<PARAM name="table" datatype="char" arraysize="*" value="dp02_dc2_catalogs.ForcedSource">
<DESCRIPTION>Table containing time series data</DESCRIPTION>
</PARAM>
<PARAM name="id_column" datatype="char" arraysize="*" value="objectId">
<DESCRIPTION>Foreign key in time series table</DESCRIPTION>
</PARAM>
<PARAM name="join_time_column" datatype="char" arraysize="*" value="dp02_dc2_catalogs.CcdVisit.expMidptMJD">
<DESCRIPTION>Foreign column spec for time retrieval</DESCRIPTION>
</PARAM>
<PARAM name="band" datatype="char" arraysize="*" value="all">
<DESCRIPTION>Filter band to retrieve (default: all)</DESCRIPTION>
<VALUES>
<OPTION value="all" />
<OPTION value="u" />
<OPTION value="g" />
<OPTION value="r" />
<OPTION value="i" />
<OPTION value="z" />
<OPTION value="y" />
</VALUES>
</PARAM>
<PARAM name="detail" datatype="char" arraysize="*" value="principal">
<DESCRIPTION>Level of detail for time series (default: principal)</DESCRIPTION>
<VALUES>
<OPTION value="full" />
<OPTION value="principal" />
<OPTION value="minimal" />
</VALUES>
</PARAM>
</GROUP>
</RESOURCE>
A client aware of the relevant IVOA protocols, such as the Portal Aspect, can use these service descriptors to present a UI to the user for additional required parameters for the linked services and then make calls to those services to obtain additional data.
Links service¶
Currently, the supported mechanism for locating images from obsevations is to make a TAP query against the ObsCore schema.
There are two supported ways of linking to the underlying image in a result row from an ObsCore query: putting a URL for the image into the access_url column, or putting a link to a DataLink links service into the access_url column.
Rubin Observatory data sets are restricted to data rights holders by default, so the image links require authentication. Given other architectural design constraints of the Rubin Science Platform at the IDF, the easiest way to provide an authenticated link to the image is a pre-authenticated Google Cloud Storage or S3 link with a short expiration, accessible only via an authenticated query. Since these links by necessity change constantly, they cannot be put directly into the database tables underlying the ObsCore schema. Using a DataLink links service URL allows storing static links in the underlying database table while still authenticating access to images. We therefore use the latter approach.
Here is the architecture in diagram form:
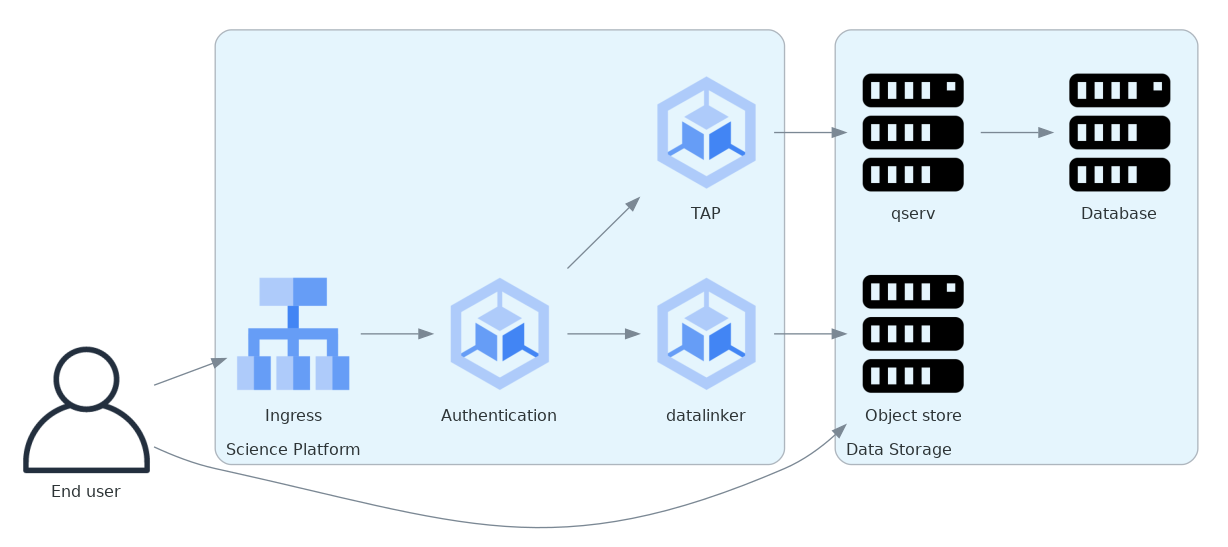
Figure 1 Shows a generic version of the overall architecture that can be built on top of Google Cloud Storage or S3 storage. Technically, the ingress asks the authentication service for verification and then sends the request directly to the service, but conceptually authentication sits in front of the service as is shown here.¶
And here is an interaction diagram of the flow involved in retrieving a specific image:

Figure 2 Sequence of operations for image retrieval. The authentication and authorization check in front of every Science Platform request has been omitted for clarity. See DMTN-234 for details on authentication and authorization.¶
In addition to providing a link to the image, we also want to provide pointers to associated services, most notably a SODA image cutout service. There are two basic ways to do this: return the service descriptor directly with the TAP table, or use a pointer to an external DataLink links service and attach the service. Since we are using a DataLink links service anyway, attaching the service descriptor there is simpler and keeps all the metadata about the image together. This will allow us, for example, to point a future SIA service at the same DataLink links service and thus easily provide the same service descriptors.
Implementation¶
The access_url column for each observation with a corresponding retrievable image is set to <rsp-base-url>/api/datalink/links?ID=<id> where <rsp-base-url> is the base URL [1] for the corresponding instance of the Rubin Science Platform and <id> is a unique identifier for that image in Butler.
To indicate that this is a URL to a DataLink service, the access_format column is set to application/x-votable+xml;content=datalink.
We also add a service descriptor to the TAP result indicating that access_url is a link to a DataLink links service.
The access_url goes to a separate service called datalinker.
The provided ID is opaque to datalinker; it only passes it to the Butler and asks for the storage URL, the URL either pointing to GCS or S3 for the underlying image.
datalinker then creates a signed URL for that image that is valid for an hour and generates a DataLink links response (including any relevant service descriptors, such as the cutout service) to the user.
Because the return from the DataLink links service grants direct access to an image, this route requires read:image scope.
Note that this usefully separates TAP query permissions from image access permissions: the ObsTap query to get metadata requires read:tap scope, but the user then needs read:image scope as well to get the underlying image.
Service descriptors¶
The second place we use DataLink is to provide easy access to additional queries related to the results of a TAP query. We add those service descriptors to the VOTable returned by the TAP query, pointing to a URL provided by the datalinker service with parameters filled in either by elements from the row of the query or by data entered by the user. That service, in turn, constructs a new TAP query and redirects the user back to the TAP service to perform that query.
For example, one of the additional queries we provide retrieves a light curve for an object.
We attach that service descriptor to any results that include the objectId column of the Object table.
The access URL of the DataLink entry points to <rsp-base-url>/datalink/timeseries.
This URL takes the following parameters:
idis set to the value ofobjectIdtable(the table containing time series data) is set to theForcedSourcetableid_column(the foreign key in that table) is set toobjectIdjoin_time_column(the column containing the observation time) is set to theexpMidptMJDcolumn in theCcdVisittablebandis up to the user to choose from the valuesallor any one ofugrizydetailis up to the user to choose fromfull,principal, orminimal(discussed further in datalinker links configuration)
This is just an example; the details are specific to this one schema and not horribly important. The general principle is that any result column can be linked to a service, specifying some mix of fixed parameters (based on the result row or on known details of the table to which the DataLink service descriptor is attached) and user-chosen parameters. The Portal Aspect and other IVOA clients can then prompt the user for the required parameters and construct an access URL for that service.
When that URL is visited, the effect will be to execute a new TAP query and return the result as a new VOTable. That VOTable can, in turn, have new service descriptors, allowing the user to follow these service prompts to explore the data further if they choose.
Making this all work involves several moving parts.
TAP configuration¶
Each of these DataLink service descriptors is defined in an XML file in the sdm_schemas repository.
This is a verbatim copy of the service descriptor to return, apart from an <INFO> tag that describes the column to which the service descriptor is attached.
<INFO name="$dp02_dc2_catalogs_Object_objectId$"
ID="$dp02_dc2_catalogs_Object_objectId$"
value="this will be dropped..." />
A parameter in the resulting DataLink service descriptor will then look like:
<PARAM name="id" datatype="long" ref="$dp02_dc2_catalogs_Object_objectId$"
value="" ucd="meta.id">
In the DataLink service descriptor returned to the client, that ref value will be replaced with a reference to the corresponding column in the result VOTable.
All DataLink service descriptors are described in a JSON manifest file named datalink-manifest.json.
This is a JSON object, the keys of which are the names of the XML files found in the same directory that define the DataLink service descriptor, and the values are lists of columns to which that service descriptor applies.
Periods in the columns are replaced with underscores.
For example, a manifest containing only an entry for the DataLink service descriptor described above would look like:
{
"dp02_object_to_fs_timeseries": ["dp02_dc2_catalogs_Object_objectId"]
}
Each time a release is made from the sdm_schemas repository, a GitHub release artifact is created (via GitHub Actions) named datalink-snippets.zip.
The TAP service is then configured (using datalinkPayloadUrl in its values.yaml file in Phalanx) to point to that artifact.
When the TAP service is restarted, that URL is retrieved and unpacked. The Rubin Science Platform TAP service then reads that directory and uses it to annotate results.
datalinker links configuration¶
The implementation of this service on the datalinker side is conceptually simple.
It uses the parameters to construct a TAP query, and then returns a redirect to the TAP service sync API to perform that query.
Because this service is effectively a front end to TAP queries, it is protected by the read:tap scope.
The main complexity comes from the detail parameter.
The purpose of detail is to allow the user to decide what columns should be included in the query result.
The three valid values are:
- full
Include all columns of the table being queried.
- principal
Include only the principal (most generally useful) columns. These are the columns for which the
principalflag is true in the corresponding TAP schema entry.- minimal [2]
Include only the minimal columns required to follow service descriptor links to other tables of interest. This is intended for use in data exploration, where the next link in the exploration isn’t the final destination but is only being followed to reach other tables of interest.
In order to correctly respond to these requests for a detail parameter other than full, the datalinker service has to be able to look up the list of columns to include for a given table.
For principal, since this is the same as the principal columns in the TAP schema, the canonical source of this data is the underlying schema.
For Rubin Observatory, the schema definitions live in the sdm_schemas repository, and are maintained by a software package called Felis.
The principal columns are tagged with tap:principal: 1 in the Felis definition.
Therefore, to provide this information to the datalinker service, the same GitHub Actions build process that generates datalink-snippets.zip above also generates the artifact datalink-columns.zip.
This ZIP archive contains two files, columns-minimal.json and columns-principal.json, which list the minimal and principal columns for each table.
columns-principal.json is generated automatically from the Felis schema, and the columns are ordered according to the order defined by the tap:column_index attributes of each column.
There is not yet a Felis attribute for marking minimal columns, so for the time being the columns-minimal.json file is hand-maintained.
datalinker butler configuration¶
Currently, datalinker calls Butler directly and therefore has to be configured with the storage used by Butler, as well as the PostgreSQL database the Butler uses to find the files in the metadata. In order for the Butler to connect to the PostgreSQL server, known as a Butler repository, the PGUSER and PGPASSFILES must be set. These are typically loaded from the vault containing the secrets for the environment.
Depending on the environment, the storage for the Butler may be hosted on Google, or a privately hosted S3. To configure this, first set the STORAGE_BACKEND to either GCS or S3. If GCS is chosen, set the S3_ENDPOINT_URL to https://storage.googleapis.com (the default). If S3 is chosen, set S3_ENDPOINT_URL to the base http URL of the private S3 service. Many of these secrets come from the vault containing the secrets for the environment.
No matter if GCS or S3 is chosen, these credentials are used to sign the image URLs.
Future work¶
Once client/server Butler (DMTN-176) is available, datalinker is expected to use it for the query and request a signed URL directly from it rather than signing its own.
Currently, each time there is a new release of the schemas, the Phalanx configuration of both datalinker and TAP have to be updated to pick up the new versions of the release artifacts they use for configuration. This creates an unwanted opportunity for version mismatches between components of a given Science Platform deployment.
In the future, rather than use the current mechanism of directly retrieving artifacts from GitHub, we plan to have the tap-schema service, which already serves the TAP schema database, to also deploy a microservice that provides this data. TAP and datalinker will then query that service within the same Science Platform deployment, and the data returned by the service will always match the deployed version of the TAP schema.
The
minimalvalue of thedetailparameter is currently not fully defined and hasn’t been tested against what types of data explorations users may wish to perform.